Basic Machine Learning In R - IRIS
이 글은 작성자가 Edwith 강의의 멘토로 활동하면서 수강생들의 이해를 돕기 위해 쓴 글입니다. 매우 친절하게 설명되어 있으므로, 다른 분들이 보셔도 무방합니다.
안녕하세요, 아낌없이 주는 나무 2회차 강의를 듣고 오신 여러분. 이 글에서 R 코드를 설명해드리겠습니다. R_machine_learning.R을 열어 글을 읽으며 하나씩 실행시켜 보세요. (+iris.xlsx도 다운로드받아주세요.)
iris.xlsx에는 붓꽃들의 정보가 담겨있습니다. 붓꽃의 줄기 같은 길이 등을 측정하고, 그 붓꽃의 품종과 이를 측정한 기록원의 이름이 있습니다. 우리는 저러한 길이 정보들을 토대로 붓꽃의 품종들을 예측해볼 것입니다.
한 줄을 실행하기 위해서는, 그 위치에 커서를 놓고 CTRL+ENTER를 쳐야 합니다. 여러 줄을 실행하기 위해서는, 해당 줄 전체를 드래그하고 CTRL+ENTER를 쳐야 합니다. 만약 정상적으로 파일이 열렸다면 다음과 같은 화면이 떠야 합니다. 이때 우측 상단, 하단은 다를 수 있으나 별 문제는 없습니다. 또한 색깔이 아마 다를텐데, 제가 따로 어둡게 설정했기 때문으로 이 또한 상관없습니다.
이 코드로 사용할 package들을 다운로드받습니다. package는 앞으로 사용할 도구들의 집합체입니다.
#Installing package
install.packages("dplyr")
install.packages("caret")
install.packages("readxl")
install.packages("doParallel")
install.packages("rattle")
다운받은 package들을 library, 즉 사용하겠다고 컴퓨터에게 알려줍니다.
#Using package
library(dplyr)
library(readxl)
library(caret)
library(doParallel)
library(rattle)
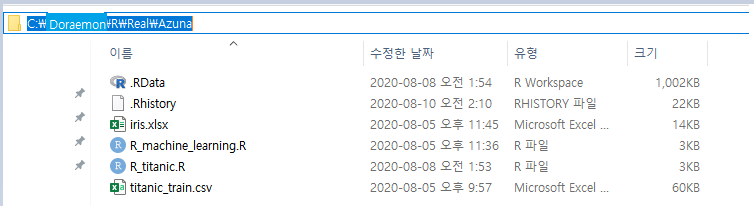
엑셀 파일을 R 환경으로 불러왔습니다. 이때 주의할 점이 있습니다. setwd()는 경로를 지정해주는 함수입니다. 파일을 다운로드받은 경로를 "" 안에 넣어주어야 하며 경로에 존재하는 \를 /로 바꾸주어야 합니다. 아래 사진을 참고하세요.
summary()는 간단히 데이터를 요약해주는 함수입니다. 실행시켜보시면 하단에 iris.xlsx에 대한 정보가 출력되는 것을 볼 수 있습니다.
#Download data
setwd("C:/Doraemon/R/Real/Azuna")
data <- read_excel("iris.xlsx")
summary(data)
오른쪽 상단 창에서 data를 클릭하면 이렇게 iris.xlsx 전체를 보실 수 있습니다.

그런데, 붓꽃의 품종을 예측하는 데에 있어서 기록원의 이름이 중요할까요? 전혀 그렇지 않을 겁니다. 기록원의 이름으로 품종을 예측하는 것은 무의미할 뿐더러 예측을 오히려 어렵게 하는 요소로, 제거해줄 필요가 있습니다. 여기서는 select 함수를 사용했습니다. 또한 중간에 기록되지 않은 값이 있으면 에러가 발생하기 쉽습니다. 우리는 이런 값을 결측치라 부르고, 결측치를 처리할 때 이를 평균/중간값으로 대체해주기도 하지만 저희는 결측치가 들어있는 붓꽃 데이터를 na.omit 함수로 제거해주었습니다.
data <- data %>% select(-`Examiner's_name`)
table(is.na(data))
data <- na.omit(data)
더 나아가기 전, select에 대해 더 자세하게 알아보겠습니다. data에서 어떤 열을 제거하고 싶을 때는 위처럼 data <- data %>% select (-제거할 열 이름), 어떤 열만을 추출하고 싶을 때는 data <- data %>% select(추출할 열1 이름, 추출할 열2 이름)으로 해야 합니다.
한편 boxplot 함수를 이용해 데이터의 분포를 살펴봅시다.
boxplot(data$`sepal_length`)
boxplot(data$`sepal_width`)
boxplot(data$`petal_length`)
boxplot(data$`petal_width`)
이때 `sepal_width`에서만 이상한 점들이 관찰됩니다. 이것은 이상치라 불립니다. 이상치는 다른 데이터들에 비해 지나치게 크거나, 작은 값으로 적합하지 않은 머신러닝 모델들을 만들어내는 데에 기여하기도 합니다. 따라서 이런 이상치들이 포함된 붓꽃을 제거하고 다시 확인해주었습니다.
data <- data[data$`sepal_width` <= 4 & data$`sepal_width` >= 2.2, ]
boxplot(data$`sepal_width`)
곧 수행할 모델 훈련, 모델 정확도 측정을 30번할 계획이므로 사용할 parameter num을 30으로 설정했습니다.
num=30
30개의 정보들을 담을 수 있는 구조들을 만들어주었습니다. 우리는 여기에 향후 제작할 모델들의 정확도 정보를 저장할 것입니다.
accuracy_dt <- accuracy_dt2 <- accuracy_rf <- accuracy_svm <- vector(length=num)
시간을 절약하기 위해 컴퓨터의 성능을 최대한으로 활용하는 코드입니다. 만약 컴퓨터의 성능을 전부 활용하지 않고 싶다면, 이 코드를 실행하지 않거나 detectedCores()-1 로 바꿔주세요.
registerDoParallel(detectCores())
조금 어려운 부분입니다. 간단히 설명하면, 조금 뒤 일부 모델에서 특정 정보가 중요하게 강조되는 것을 막기 위해 pp를 사용할 수 있습니다. 또한 ctl은 뒤에서 모델들의 신뢰성과 성능, 모델링 속도를 향상하기 위해 사용할 것입니다. 이를테면 교차검증 등의 모델 학습 방법들을 지정 및 구체화하거나 병렬처리를 허용하며 최종 모델을 선택하는 방식을 설정합니다.
pp <- c("center", "scale")
ctl <- trainControl(method="repeatedcv", number=5, repeats=5, allowParallel=T, savePredictions="final")
이 글의 하이라이트입니다!! 직접 예측 모델을 만들고, 이를 평가하는 코드입니다.
#Data split
for(i in 1:num){
코드
}
이런 for문은 코드를 num번 반복하게 만듭니다. 여기서는 30번이겠네요.
idx에는 어떤 데이터를 train으로 사용할지에 대한 정보를 담고 있습니다. createDataPartition()이 바로 trian, test를 구분해주는 함수이기 떄문이죠. idx를 기반으로 triandata, testdata를 분획해주었습니다.
#Modeling
예측 모델은 train 함수를 통해 제작합니다. train 함수는 이렇게 사용합니다.
train(종속변인(target)~독립변인(feature), data, method, trControl, preProcess)
우리 데이터의 target은 kind이고, feature는 kind를 제외한 모든 변인입니다. R에서는 이를 kind~. 로 표현합니다. 또한 1회차에서 설명드렸듯 traindata만으로 데이터를 훈련할 것입니다. method에는 사용할 알고리즘의 이름을 적어주면 됩니다. 이곳에서 사용한 알고리즘은 4가지, rpart, rpart2, rf, svmLinear3입니다. rpart, rpart2는 의사결정트리이고, rf는 많은 수의 의사결정트리를 사용한 알고리즘, svmLinear3는 support vector machine이라는 알고리즘들 중 하나입니다. 이때 rpart, rpart2에서는 preProcess를 지정해주지 않아도 됩니다. (그러나 대부분의 알고리즘은 preProcess를 필요로 합니다.) trControl은 모든 모델에 지정해주는 것이 좋습니다.
이외의 알고리즘들을 찾고 싶으면 이 사이트를 방문해주세요. method value 열을 참고하시면 됩니다.
topepo.github.io/caret/available-models.html
6 Available Models | The caret Package
Documentation for the caret package.
topepo.github.io
#Evaluation
postResample 함수는, 모델의 성능을 평가합니다. 이곳에선 앞에서 만든 모델이 testdata를 얼마나 정확하게 평가했는지 계산합니다.
for(i in 1:num){
print(i)
#Data split
idx = createDataPartition(data$kind, p=0.7, list=F)
traindata <- data[idx,]
testdata <- data[-idx,]
#Modeling
dt_clf <- train(kind~., data=traindata, method="rpart", trControl=ctl)
dt2_clf <- train(kind~., data=traindata, method="rpart2", trControl=ctl)
rf_clf <- train(kind~., data=traindata, method="rf", trControl=ctl, preProcess=pp)
svm_clf <- train(kind~., data=traindata, method="svmLinear3", trControl=ctl, preProcess=pp)
#Evaluation
accuracy_dt[i] <- postResample(pred = predict(dt_clf, testdata), obs = as.factor(testdata$kind))
accuracy_dt2[i] <- postResample(pred = predict(dt2_clf, testdata), obs = as.factor(testdata$kind))
accuracy_rf[i] <- postResample(pred = predict(rf_clf, testdata), obs = as.factor(testdata$kind))
accuracy_svm[i] <- postResample(pred = predict(svm_clf, testdata), obs = as.factor(testdata$kind))
}
이제 각 알고리즘의 정확도를 비교해봅시다. 30번 평균 정확도는 이렇게 알 수 있습니다.
mean(accuracy_dt)
mean(accuracy_dt2)
mean(accuracy_rf)
mean(accuracy_svm)제 컴퓨터에선 이렇게 나왔습니다. rf 알고리즘 모델의 정확도가 가장 높게 나왔지만, 거의 차이가 없어 모든 모델들을 채택하여 분석해보겠습니다.
> mean(accuracy_dt)
[1] 0.9426357
> mean(accuracy_dt2)
[1] 0.9426357
> mean(accuracy_rf)
[1] 0.9457364
> mean(accuracy_svm)
[1] 0.9341085varImp 함수는 variables of importance, 즉 모델에서 각 변인이 갖는 상대적 중요도를 출력합니다. 이를테면 다음 예시에선 dt_clf, 곧 rpart 기반 모델에선 petal_width의 중요성이 100이라면 sepal_length는 29.34 정도로 종속 변인(target)에 영향을 미칩니다.
varImp(dt_clf)rpart variable importance
Overall
petal_width 100.00
petal_length 92.20
sepal_length 29.34
sepal_width 0.00varImp(dt_clf)
varImp(dt2_clf)
varImp(rf_clf)
varImp(svm_clf)
이전에 잠시 언급했듯, 의사결정트리(rpart)는 매우 직관적인 시각화가 가능합니다. 따라서 dt2_clf 모델을 시각화해보겠습니다. fancyRpartplot 함수가 특히 보기 좋게 시각화해줍니다.
fancyRpartPlot(dt2_clf$finalModel)이를 해석해보겠습니다. 어떤 미지의 붓꽃이 petal_length는 3, petal_width는 1.5, sepal_length는 2, sepal_width는 1라고 합시다. 맨 위의 Node에서 petal_length < 2.5 이 아니므로 오른쪽, 오른쪽 Node에서 petal_width < 1.8 이 맞으므로 왼쪽 Node, 왼쪽 Node가 versicolor이므로 의사결정트리 모델은 이 붓꽃이 versicolor 품종이라 예측합니다.

이런 시각화를 지원하지 않는 대다수의 모델들의 예측 결과는 이렇게 확인합니다. data.frame 함수 안에 예측할 데이터의 정보를 입력하고, predict 함수를 이렇게 사용합니다.
prediction <- data.frame(sepal_length=5, sepal_width=3.3, petal_length=0.2, petal_width=0.4)
predict(dt_clf, prediction)
predict(dt2_clf, prediction)
predict(rf_clf, prediction)
predict(svm_clf, prediction)sepal_length가 5, sepal_width가 3.3, petal_length가 0.2, petal_width가 0.4인 붓꽃은, 4가지 모델 모두 setosa로 예측했습니다.
> predict(dt_clf, prediction)
[1] setosa
Levels: setosa versicolor virginica
> predict(dt2_clf, prediction)
[1] setosa
Levels: setosa versicolor virginica
> predict(rf_clf, prediction)
[1] setosa
Levels: setosa versicolor virginica
> predict(svm_clf, prediction)
[1] setosa
Levels: setosa versicolor virginica
지금까지 R에서 머신러닝을 구현하는 방법을 초심자 수준에서 살펴봤습니다. 아낌없이 주는 나무 수강생 여러분들은 3회차 강의 업로드 전까지 titanic_train.xlsx로 실습해보시면 되겠습니다. 질문사항이 있으면 언제든지 Edwith에 댓글 달아주세요.