PCA(주성분분석, Principal Component Analysis)의 수학적 원리
I. PCA는 무엇인가
PCA(Principal Component Analysis)는 대표적인 차원 축소 기법입니다. 데이터의 차원을 축소하는 이유 중 하나는 차원의 저주입니다. 차원의 저주는, 데이터의 Feature가 증가할수록 정확한 예측을 하기 위해 필요한 데이터의 양이 기하급수적으로 증가하는 현상입니다. 예를 들어 라면의 특징들을 기반으로 라면의 평점을 예측하는 인공지능을 모델링하는 상황을 생각해봅시다. 이때 확보한 데이터에 라면의 종류는 100개, 라면의 특징이 1000종류가 포함되어 있다면 어떨까요. 자명하게도 1000가지의 Feature가 동등하게 예측에 사용된다면, 겨우 100가지의 표본만이 존재하기 때문에 학습이 정상적으로 이루어질 수 없습니다. 아래 사진에서 알 수 있듯이 같은 양의 데이터가 더 많은 차원을 가질수록, 그 밀도가 급격히 낮아지기 때문입니다.

이런 문제를 해결하기 위해 흔히 PCA를 사용합니다. (그 외에도 시각화, Feature 분석 등등을 위해서 사용됩니다.) PCA는 Feature들의 적절한 선형결합을 통해 새로운 Feature을 구성합니다. 이제부터 그 수학적 원리를 살펴보겠습니다.
II. PCA의 목표
PCA는 사영시켰을 때 (센터링된) 데이터의 분산을 최대화하며 서로 직교하는 unit vector들을 찾습니다. 즉 데이터를 잘 표현할 수 있는 새로운 orthonormal basis를 찾고자 합니다. 이것이 무슨 의미인지 조금 더 살펴보겠습니다. 사진은 http://alexhwilliams.info/itsneuronalblog/2016/03/27/pca/에서 가져왔습니다.
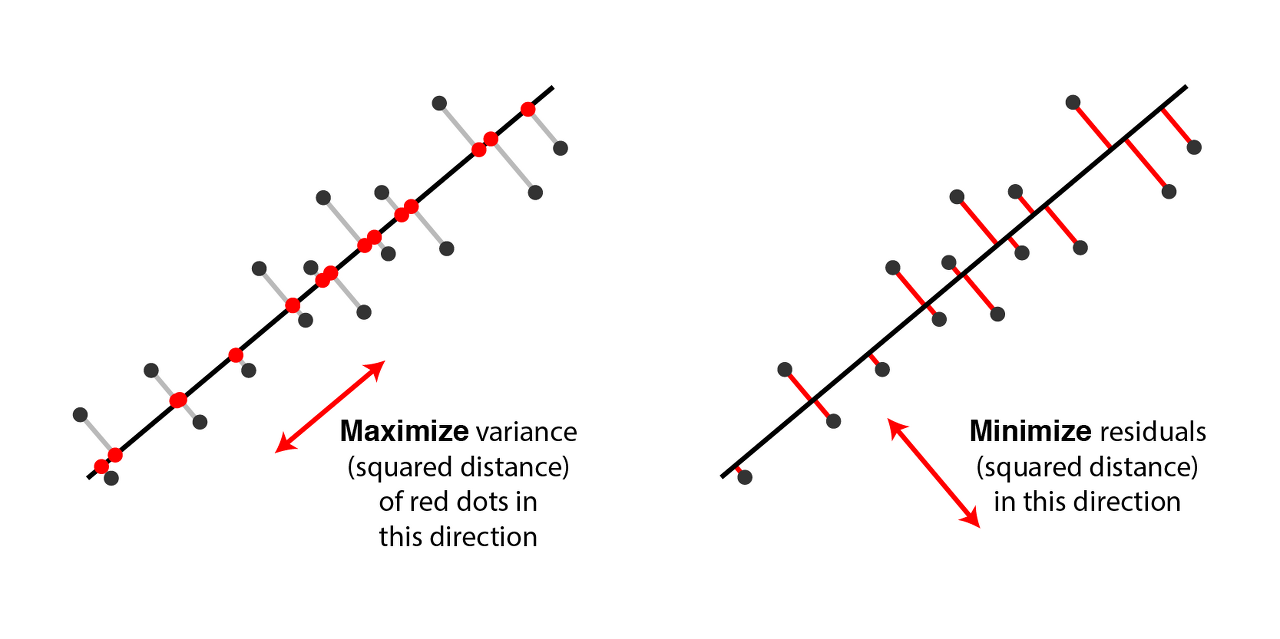

우선 데이터가 센터링되어 있다고 가정합시다. 즉 데이터의 각 Feature들의 평균이 0이라고 합시다.

센터링된 데이터 벡터들 중 하나를 $v_i$, 정사영시킬 1차원 벡터를 $u$라고 하면, 정사영된 벡터는 $\langle cu, v_i -cu \rangle=0$을 만족하는 스칼라 c에 대하여 $cu$가 될 것입니다. 따라서 피타고라스 정리에 의해 $\|v_i\|^2 = \|cu\|^2 + \|v_i -cu\|^2$가 성립합니다.
이때 $\sum \|v_i\|^2$는 고정값이므로 $\sum \|cu\|^2$가 커지면 $\sum \|v-cu\|^2$는 작아집니다. 이때, 데이터가 센터링되었으므로 $\mathbb{E}(cu)=\vec 0$이라서 $\sum{\|cu\|}^2 = N \mathbb{E}({\|cu\|}^2) = N\mathrm{Var}(cu)$ 가 성립합니다. 즉 $\sum\|cu\|^2$는 분산에 데이터의 개수 N을 곱한 꼴입니다. 즉, 분산을 최대화하는 것은 곧 $\sum\|v-cu\|^2$을 최소화하는 것입니다. 이때 $\sum \|v-cu\|^2$는 일종의 Residual sum, 다시 말해 $v_i$와 $u$ 사이의 거리들의 제곱의 합입니다. 따라서 분산의 최대화는 잔차의 최소화와 동일한 말입니다. 요약하자면, PCA는 Linear regression처럼 데이터들을 가장 적절하게(가깝게) 사영시킬 수 있는 벡터를 찾고자 합니다.
III. PCA Computation
1. Centering
앞서 말한 이유로 모든 Feature의 평균이 0이 되도록 평균을 빼줍니다. 위에 업로드한 그림을 보시면 이해가 잘 되실 겁니다.
이제부터 센터링된 데이터 행렬을 $X \in Mat_{m \times n}$이라 하겠습니다. (m개의 데이터, n개의 feature)
*정확한 이해: Centering은 PCA에 포함되는 과정이 아닙니다. 다만 후속 과정이 각 feature의 기댓값이 0임을 가정하기 때문에, 독자의 이해를 돕기 위해 편의상 넣어주었을 뿐입니다. 명백하게 feature의 기댓값이 0인 상황이 아니면 centering이 전처리 과정에 반드시 속해야 합니다. Sample mean과 모평균의 관계를 생각해보면 이해가 되실 겁니다.
2. Maximizng variance
이 부분을 이해하기 위해서 Linear algebra, 기초통계, vector calculus를 알고 계셔야 합니다.
앞으로 사용되는 inner product $\langle \cdot, \cdot \rangle$은 Standard inner product입니다.
(1) 1st component
우선 사영시킨 후 분산이 최대화되는 unit vector $\vec e_1$을 구해봅시다. X를 $\vec e_1$에 사영시킨 벡터의 길이(마이너스까지 고려: 예를 들어 $-3\vec e_1$ 이면 -3)는 $X \vec e_1$입니다. $proJ_{\vec e_1} x_i = \frac{\langle x_i , \vec e_1 \rangle}{\| e_1 \|} e_1 = \langle x_i , e_1 \rangle \vec e_1$이기 때문입니다.
따라서, $\mathrm{Var}(X \vec e_1 )=\mathbb{E}( \| X \vec e_1 \| ^2) = \frac{1}{m-1} \vec {e_1}^T X^T X \vec{e_1}$이 성립합니다. 이때 Feature들 사이의 covariance matrix를 $\Sigma$라고 하면, $\Sigma = \frac{1}{m-1} X^T X$임을 활용하여 $\mathrm{Var}(X \vec e_1)=\vec{e_1}^T \Sigma \vec e_1$로 쓸 수 있습니다. $\Sigma$는 고정값이므로 $\vec{e_1}^T \Sigma \vec e_1$ 을 최대화하는 unit vector $\vec e_1$을 찾아야 합니다.
(2) Lagrange multipler method
이러한 $\vec e_1 $는 Lagrange multipler method를 이용하여 찾을 수 있습니다. Unit vector라는 제약조건에서 위 식을 최대화해야 하므로, $L(\vec e_1 , \lambda) = \vec{e_1}^T \Sigma \vec e_1 - \lambda (1- \vec{e_1}^T \vec{e_1})$로 보조 함수를 정의합니다. 이때 $\frac{\partial L}{\partial \vec e_1} = 0$이어야 하므로 $2\Sigma \vec e_1 = 2\lambda \vec e_1$이 성립합니다. 따라서, $\vec e_1$은 Covariance matrix의 eigenvector이고, 이 관계를 분산의 식에 대입하면 분산이 그 eigenvalue임을 알 수 있습니다. 따라서 이를 정리하면 $\vec e_1$은 Covariance matrix의 가장 큰 eigenvalue에 대응하는 unit eigenvector입니다.
(3) The other components
매우 유사한 과정을 거쳐 다른 unit vector들을 찾을 것입니다. PCA의 목표에 부합하도록 이렇게 도출된 n개의 벡터들은 orthonormal basis를 이뤄야 합니다. 우선 $\vec e_2$를 먼저 찾아보겠습니다. $\vec e_1$과 직교하면서 variance를 최대화할 수 있어야 하므로.. 보조함수 L이 $L(\vec e_2 , \lambda, \beta) = \vec{e_2}^T \Sigma \vec e_2 - \lambda (1- \vec{e_2}^T \vec{e_2}) - \beta \vec{e_1}^T \vec e_2$으로 살짝 변형됩니다. 그리고 Lagrange multipler method에 따라 아래 두 식이 성립해야 합니다.
1. $\frac{\partial L}{\partial \vec e_2}$ = 0 => $\Sigma \vec e_2 = \lambda \vec e_2 + \beta \vec e_1$
2. $\frac{\partial L}{\partial \beta}=0$ => ${\vec e_1}^T \vec e_2 = 0$
1번 식에 $\vec e_1 ^T$를 곱하면, $\beta=0$임을 알 수 있습니다. 따라서 결국 $\vec e_2$도 Covariance matrix의 egienvector이고, 두 번째로 큰 eigenvalue와 대응됩니다. 나머지 component들도 마찬가지입니다.
정리하자면, PCA 결과 변환되는 Orthonormal basis는 Covariance matrix의 (unit) eigenvector들로 구성됩니다. 각 성분에서의 Variance는 그 eigenvector의 eigenvalue와 같습니다.
IV. Singular Value Decomposition: For faster PCA
그럼에도 불구하고, Covariance matrix의 고유벡터를 구하는 과정은 시간복잡도가 매우 높습니다. 이에 따라 PCA의 연산량을 줄이기 위한 방법으로 실전에서는 SVD가 주로 활용됩니다. PCA의 주 목적이 차원 축소이고 실제 데이터에서 2~3차원의 성분만 활용하는 경우가 허다하기 때문입니다. 다시 말해 전체 고유벡터를 계산하지 않고 Eigenvalue가 큰 몇 개의 eigenvector들만 구해도 분석에 지장이 없습니다. SVD의 경우 이런 몇 개의 벡터를 찾아내는 빠른 알고리즘들이 개발되어 있습니다!
SVD를 한 장에 요약하면 아래 사진과 같습니다. (이전에 본인이 만든 발표용 PPT입니다. 추후에 이와 관련된 글을 작성할 수도 있습니다.) 결과적으로 SVD와 PCA가 찾고자 하는 벡터들이 일치함을 확인할 수 있습니다.

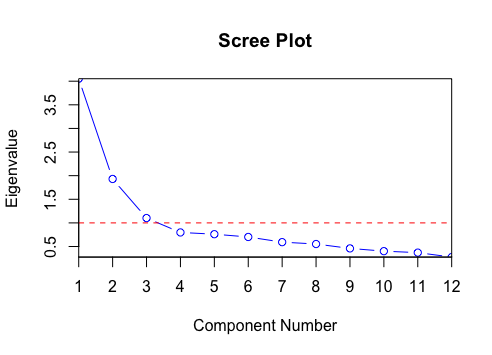
V. 성분 개수 결정: Elbow method
차원 축소를 위해서는 몇 가지 eigenvector만을 활용해야 합니다. 이를 위해 일반적으로 scree plot을 활용합니다. scree plot은 아래 그림처럼 각 eigenvector들의 eivenvalue를 시각화합니다. eigenvalue는 곧 사영된 벡터들의 variance를 의미하므로 이를 그 vector가 데이터를 설명하는 정도로 해석하여 y축을 $\frac{\lambda_i}{\sum \lambda_i}$로 설정하기도 합니다.
이 Scree plot의 곡선 개형이 제 3성분부터 크게 꺾이고 있습니다. 이렇게 급격하게 곡선의 개형이 꺾이는 부분까지의 성분만을 선택하는 것이 elbow method입니다. 이 이후부터의 성분들을 선택해도 데이터의 표현력이 크게 증가하지 않기 때문입니다. 이렇게 제 1~3성분만을 선택해도 충분히 이 3개의 성분만으로 데이터의 정보들을 꽤 담아낼 수 있으므로, PCA의 목적에 부합합니다.
VI. PCA에서 주의해야 할 점들
(1) Centering
앞선 서술에서 데이터들이 centering되어 있다고 가정하였습니다. 위에 언급하였듯이 PCA가 Feature들의 기댓값이 0임을 가정하므로 일반적으로 Sample mean이 0이 되도록 전처리가 필요합니다.
(2) Scaling
특별히 한 Feature가 담고 있는 정보에 가중치를 주고 싶지 않다면 반드시 각 Feature들의 표준편차가 1이 되도록 Scaling을 해주어야 합니다. 그렇지 않으면, 유난히 scale이 큰 feature가 존재했을 때 사영시켰을 때 분산을 최대화하는 방법은 단순히 그 feature의 방향으로 사영벡터를 설정하는 것이 됩니다.
(3) Euclidean space
PCA 내내 standard inner product를 활용했습니다. (Variance 등식 등..) 따라서 Euclidean space에 있지 않은 데이터들은 PCA를 활용할 수 없습니다.
Written by Killer T Cell