
티스토리 뷰
안녕하세요, 아주나 2회차 강의 python 코드 설명을 위한 글입니다. 우선 이 글은 edwith에 첨부된 파일 iris.xlsx를 이용하니 edwith에서 데이터가 저장된 파일 iris.xlsx를 먼저 다운받아 주세요.
우선 데이터로 사용할 iris.xlsx에 대해 간단한 설명을 드리자면 붓꽃(iris)의 꽃잎과 꽃받침의 너비와 길이를 통해 붓꽃의 세 가지 품종 중 하나의 품종을 맞추는 유명한 머신러닝 예제를 저희가 일부 변형하여 만들어낸 데이터입니다. 구체적인 내용은 코드를 통해 데이터를 함께 파악해봅시다.
Jupyter notebook이나 colab의 사용법은 매우 비슷한데요, 코드를 삽입할 수 있는 사각형이 있고 이를 셀(Cell)이라고 합니다. 이 부분에 코드를 치고 Ctrl+Enter 또는 Shift+Enter를 치면 해당 셀의 코드들을 실행할 수 있게 됩니다. 셀에는 코드 뿐만 아니라 코드에 대한 설명을 추가할 수 있도록 속성을 Markdown 등 다양하게 변경할 수 있습니다. 셀 옆에 적힌 숫자는 코드를 실행한 순서로 현재 어떤 순서로 코드가 실행되었는지를 나타내 줍니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline이 부분에서는 이후에 사용할 다양한 도구들(함수, 객체)을 사용하겠다고 선언하는 것인데요, 원래 다운로드를 받아야 하지만 Jupyter notebook이나 colab에서는 기본적으로 다운로드가 되어있어 다운로드 과정은 생략하겠습니다.
"import □ as ■" 의 형태를 띠고 있는 것을 볼 수 있는데요, 나중에 도구들을 사용할 때 어디서 가져온 도구인지를 밝혀주어야 합니다. 하지만 볼 수 있듯 □들을 계속해서 입력하기에는 너무 길어 코드를 칠 때와 읽을 때 모두 불편할 수 있는데요 그래서 뒤에 "as ■"를 통해 앞으로 ■로 간단히 부르겠다는 의미입니다. "as ■"를 빼더라도 뒤에 나올 코드들의 도구를 가져와 사용하는 부분에서 수정해준다면 문제가 없습니다.
"%matplotlib inline"는 그래프를 보기 편하게 직접 나타내라는 명령 정도로 이해하면 될 것 같습니다.
데이터 불러오기
iris = pd.read_excel('iris.xlsx')
iris.head(5)이 부분은 데이터를 불러오는 부분입니다. 첫 번째 줄은 iris.xlsx를 읽어서 iris에 저장하는 코드입니다. 자, 그러면 여기에 있는 iris.xlsx는 어디에서 찾아오는 것일까요? 컴퓨터 전체? 아니면 R과 같이 경로를 먼저 설정하는 것일까요? python의 pandas의 경우 두 가지 방법이 가능합니다. 첫 번째는 컴퓨터 전체에서 경로를 설정하는 방법입니다. 이 경우에는 "C:/Users/ ..."(다를 수 있음!)의 파일 경로를 직접 붙이고 파일 이름을 써주어야 합니다. 두 번째 방법은 제가 사용한 방법으로 지금 짜고 있는 코드의 위치에서 찾는 방법으로 이 경우에는 파일 이름만을 써도 됩니다. 즉, 코드 파일과 데이터 파일이 같이 저장되어 있을 때 사용합니다. 조금 더 알아보고 싶다면 절대경로와 상대경로에 대해 알아보는 것도 좋습니다.(많이 어려운 내용은 아닙니다.)
두 번째 줄은 iris.head(5)라는 코드가 나오는데요, 여기서 iris는 위에서 우리가 데이터를 저장한 변수입니다. iris에 head(5)를 사용하게 되면 데이터에서 가장 위에서 5줄을 잘라서 가져오라는 의미입니다. 주로 표 전체를 보기에는 너무 크기 때문에 5줄만 잘라서 확인하는 용도로 사용됩니다.
iris.info()iris.describe()이 두 개의 셀은 데이터를 대략적으로 파악할 때 사용합니다. info()를 사용하면 각 세로줄별로 어떤 데이터가 들어있고 표의 크기나 어떤 유형의 값인지(정수, 소수점 있는 수(실수), 단어(문자열)) 등을 알려줍니다. describe()를 사용하면 각 세로줄별로 수가 들어있는 세로줄에 대해 평균, 최댓값, 최솟값 등의 정보를 표시해줍니다.

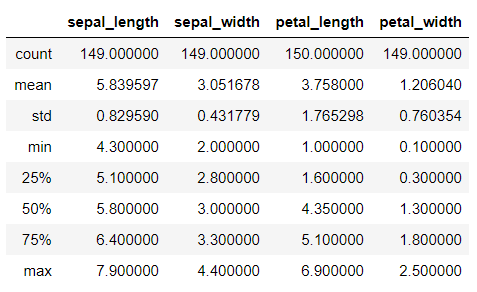
info를 보니 세로줄에는 Examiner's_name, sepal_length, sepal_width, petal_length, petal_width, kind가 있는 것을 알 수 있습니다. 그런데 붓꽃의 품종이 조사원의 이름(Examiner's_name)과 관련이 있을까요? 또한 info와 describe에서 모두 알 수 있듯이 각 세로줄별로 데이터가 150개가 있는 것도 있고 149개가 있는 것도 있습니다. 이러한 결과는 데이터에 누락된 빈 칸(결측치)이 남아있어서 나타납니다. 이러한 문제들은 예측을 잘 하는 것을 방해할 수 있고 어쩌면 오류를 발생시킬 수도 있습니다. 이러한 이유로 다음 과정을 거치게 됩니다.
데이터 전처리(가공)
위에서 데이터를 살펴보았을 때 먼저 Examiner's_name라는 세로줄을 제거하는 것이 좋을 것이라 판단했었습니다. 이 부분을 코드로 살펴봅시다.
iris.drop("Examiner's_name", axis = 1, inplace = True)
iris.head()drop이라는 함수는 데이터에서 어떤 줄을 지우는 함수인데요, 우리는 Examiner's_name이라는 세로줄을 지우고 싶습니다. 위 코드에서 axis = 1 부분이 세로줄을 의미합니다. 만약 0을 입력한 경우 가로줄에서 Examiner's_name라는 줄을 찾다가 찾지 못하면 에러를 낼 것입니다. 제거를 진행한 후 다시 head를 통해 잘 제거되었는지 확인해 봅니다. (head에서 괄호 안에 숫자를 안 쓰면 자동으로 5라고 인식합니다.)
다음으로는 결측치를 해결해보겠습니다. 우선 결측치가 얼마나 있는지 확인해보죠.
iris.isna().sum()이 코드는 결측치를 알아보고 각 줄별로 합쳐서 총 몇 개인지를 알아보는 코드입니다. 직접 실행해서 확인해 보면 0개에서 1개 정도씩 세로줄 별로 결측치가 있네요. 결측치가 많거나 결측치가 균일하지 않다면 제거하는 것에 문제가 있을 수 있지만 이 경우에는 문제가 없을 것으로 생각되니 제거하도록 합시다.
iris.dropna(inplace = True)
iris.isna().sum()첫 번째 줄은 결측치(na)를 없애는 코드이고 결측치를 없앤 후 다시 한 번 확인해 보았습니다.
다음으로 확인할 것은 이상치인데요 이것은 다른 값들에 비해 지나치게 작거나 큰 값들을 의미합니다. 이런 값들은 데이터 수집의 실수로 발생할 수도 있고 실제로 크거나 작은 값일 수도 있지만 우리가 예측하는 것에는 방해가 될 수 있으니 없애는 것이 도움이 될 때가 많습니다. 이러한 이상치를 쉽게 알아보는 방법으로는 그래프를 그려보는 것인데요, 주로 boxplot을 이용합니다.
sns.boxplot(iris['sepal_length'])
sns.boxplot(iris['sepal_width'])
sns.boxplot(iris['petal_length'])
sns.boxplot(iris['petal_width'])(이 글처럼 한 개의 셀에 한 번에 치게 되면 마지막 그래프만 그려질 것이니 따로 셀에 입력해주세요.)
그래프를 보니 막대기 밖에 점이 찍혀있는 경우도 있고 그렇지 않은 것들도 있습니다. 일반적으로 막대기 밖의 점들을 이상치로 생각하는데 그렇다면 'sepal_width'에서 이상치가 발견되네요. 그래프에서 값을 보니 약 2.2에서 4.0 까지의 데이터만을 이용하기로 결정했습니다.
iris = iris[(2.2 <= iris['sepal_width']) & (iris['sepal_width'] <= 4.0)]
iris첫 번째 줄은 sepal_width가 2.2에서 4.0 사이의 값을 가지는 데이터들만 추출하는 코드입니다. 주의할 점으로는 위에서 drop, dropna 등의 함수를 사용할 때는 함수만 실행했는데 이 경우에는 iris[...]만을 사용하지는 않고 다시 그것을 iris에 넣어주었습니다. 위에서 아직 설명하지 않은 inplace도 이와 관련되어 있습니다.
여기서는 iris.head()를 사용하지 않았는데 그러면 데이터 전체가 나오게 됩니다. 그런데 칸을 아끼기 위해 알아서 ...으로 줄여주네요.
모델 만들기
데이터의 가공이 끝났으면 다음으로는 예측을 수행하는 모델을 만들 차례입니다. 우선 아까와 같이 사용할 도구들을 가져옵니다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split다양한 방법(알고리즘)으로 예측을 수행하는 모델을 만들 수 있는데요, 여기서는 Decision Tree(의사결정트리), Random Forest(랜덤 포레스트), SVC(서포트 벡터 머신)을 사용하도록 하겠습니다. scikit-learn에 들어가보면 다양한 알고리즘들이 나와있습니다. http://scikit-learn.org
scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation
scikit-learn.org
우선 우리가 가진 데이터를 보면 예측해야하는 target인 품종 'kind'와 예측에 사용할 다양한 feature들이 함께 있습니다. 어떤 것이 예측할 것이고 어떤 것이 예측할 때 사용하는 것인지 데이터를 나누겠습니다.
X = iris[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
y = iris['kind']첫 번째 줄은 'kind'만을 제외하기 위한 코드인데 drop을 이용하면 다음과 같이 쓰는 것도 가능합니다.
X = iris.drop('kind', axis = 1, inplace = False)여기서는 inplace = False로 설정되어있네요. inplace는 원래 데이터인 iris를 직접 변경할 것인지(True), 아니면 변경한 데이터를 다른 데이터에 새로 저장할 것인지를 지정하는 부분입니다. 여기서는 inplace = False이므로 새로운 X에 'kind'를 제외한 부분을 새로 저장하겠다는 의미가 되고 원래 데이터인 iris는 아무것도 변하지 않게 됩니다. 만약 원래 데이터에서 'kind'가 사라졌다면 두 번째 줄에서 iris의 'kind'를 가져올 수 없겠죠.
num = 300
accuracy_dt = []
accuracy_rf = []
accuracy_svm = []
imp_dt = []
imp_rf = []
for i in range(num):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
dt_clf = DecisionTreeClassifier()
rf_clf = RandomForestClassifier()
svm_clf = SVC(kernel = 'linear')
dt_clf.fit(X_train, y_train)
rf_clf.fit(X_train, y_train)
svm_clf.fit(X_train, y_train)
accuracy_dt.append(accuracy_score(y_test, dt_clf.predict(X_test)))
#accuracy_dt.append(dt_clf.score(X_test, y_test))로 쓸 수도 있음!
accuracy_rf.append(accuracy_score(y_test, rf_clf.predict(X_test)))
accuracy_svm.append(accuracy_score(y_test, svm_clf.predict(X_test)))
imp_dt.append(dt_clf.feature_importances_)
imp_rf.append(rf_clf.feature_importances_)
print('Decision Tree :', sum(accuracy_dt) / num)
print('Random Forest :', sum(accuracy_rf) / num)
print('Support Vector Machine :', sum(accuracy_svm) / num)다음은 실제로 모델을 만들어 보고 정확도를 비교해보는 코드입니다. 정확도는 계속 바뀔 수 있으므로 300번 반복하여 평균을 구할 것인데 그 값을 num에 저장하였습니다. 아래에 accuracy_로 시작하는 3개의 리스트([]는 비어있는 리스트를 의미합니다. 리스트에는 여러개의 숫자나 다양한 것들을 차례로 나열할 수 있습니다.)를 만들어줍니다. 평균을 구하기 위해 여기에 각각의 정확도를 저장할 것입니다. imp_에 대해서는 뒤에서 설명하겠습니다.
for i in range(num):이라는 부분이 나오는데요, 이 부분을 통해 아래 있는 코드들을 num번 반복해서 실행할 수 있습니다. 더 정확하게는 i에 range(num)에 있는 값들을 하나씩 대입하며 반복하라는 의미인데요 range(num)이라고 쓰면 0부터 num-1까지의 숫자가 생성되므로 결국 num번 반복하게 됩니다.
이제는 반복문(for) 안을 보겠습니다. 처음 등장하는 줄은 train_test_split이라는 부분이 나오네요. 이 부분은 데이터를 train 데이터와 test 데이터로 구분해줍니다. test_size를 통해 그 비율을 조절할 수 있고요.
그 다음으로는 사용할 알고리즘에 해당하는 모델을 선언해줍니다. 선언을 한 후에는 fit이라는 함수를 통해 모델을 훈련하게 됩니다. 그 다음으로는 predict라는 함수를 통하여 새로운 데이터를 예측해볼 수 있는데요 여기에 test 데이터를 넣어 실제 값과의 정확도를 계산해줍니다. 코드상에는 accuracy 리스트에 append(뒤에 넣어주는 함수) 해 주었습니다.
for 밖으로 나오게 되면 print를 통하여 리스트에 저장된 값들의 평균을 출력해줍니다. 즉 평균 정확도가 나오겠네요. 여기서 저는 서포트 벡터 머신의 정확도가 가장 높게 나왔습니다. 물론 다시 실행해보면 값이 바뀔 수 있습니다.
그냥 예측만 하는 것보다 몇몇 방법들은 예측에서 어떤 것을 가장 중요하게 판단하였는지를 알아볼 수 있는 알고리즘들이 있습니다. 우리가 사용한 알고리즘에서는 Decision Tree와 Random Forest가 가능합니다. 그렇다면 이러한 중요도를 알아볼까요? 위의 코드에서 imp 리스트는 이 중요도를 저장하는 리스트였습니다. 반복문 안에 feature_importances_들을 계속하여 리스트에 넣어주고 있는 것을 알 수 있는데요 이 함수는 중요도를 알려주는 함수입니다. 이 또한 평균을 내서 막대그래프(barplot)로 나타내 보겠습니다.
sns.barplot(sum(imp_dt) / num, X_train.columns)
sns.barplot(sum(imp_rf) / num, X_train.columns)(이 코드도 위에서처럼 한 개의 셀에 한 번에 치게 되면 마지막 그래프만 그려질 것입니다.)

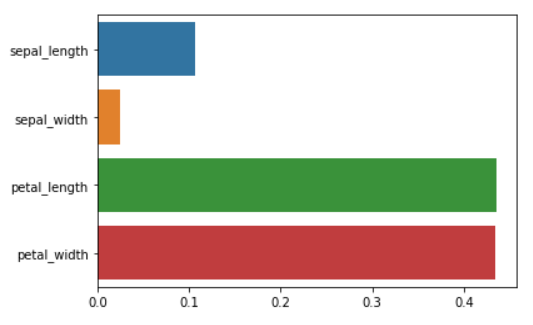
다음으로는 우리가 만든 데이터를 통해 실제로 예측을 수행해보겠습니다. 위에서 나와있듯 predict라는 함수를 통해 예측을 할 수 있습니다.
dt_clf.predict([[5.3, 2.8, 2.1, 0.6]]).item()
rf_clf.predict([[5.3, 2.8, 2.1, 0.6]]).item()
svm_clf.predict([[5.3, 2.8, 2.1, 0.6]]).item()(한 번에 쓰면 마지막 값만 나올거에요.)
대괄호를 두 번 치는 이유는 이를 1×4의 표로 인식하게 하기 위해서 입니다(1×4인 표와 그냥 길이가 4인 표는 차원이 다릅니다. 하나는 2차원이고 하나는 1차원이죠). predict 함수는 한 번에 여러 개의 예측을 하는데요 만약 n개의 예측을 한 번에 하고 싶다면 n×4의 표를 넣어주면 됩니다. 4는 위에서 fit하는 과정에서 결정되었고요. 같은 이유로 결과값도 표로 나오게 되는데 이 경우는 길이가 n인 표가 나오게됩니다. 표에서 값만을 가져오라는 의미로 뒤에 item을 붙여주었는데 붙이지 않더라도 큰 상관은 없습니다.
지금까지 python에서 머신러닝을 구현하는 방법을 초심자 수준에서 살펴봤습니다. 아낌없이 주는 나무 수강생 여러분들은 3회차 강의 업로드 전까지 titanic_train.xlsx로 실습해보시면 되겠습니다. 질문사항이 있으면 언제든지 Edwith에 댓글 달아주세요. R 설명 글에서 똑같이 가져왔어요.
'Machine Learning' 카테고리의 다른 글
| Basic Machine Learning In R - IRIS (0) | 2020.09.22 |
|---|---|
| Caret Package - Tuning(Grid Search, Random Search) in R (0) | 2020.08.29 |